Не уверен, что нужно отдельно останавливаться на работе FineReader, инструкций в интернете огромное количество, перечислю только важные моменты.
В настройках меняем язык, вместо «Русский и английский» указываем только «Русский», таким образом мы предотвращаем ситуации, когда фамилии, имена или отчества частично набраны кириллицей, частично латиницей. «Иванов» и «Ивaнoв» выглядят одинаково, но в поиске второго Иванова найти не получится.
Необходимо запустить анализ документа и проверить корректность автоматически определенных областей на каждой странице. Сканы содержат большое количество мусора, из-за этого текстовые области программа может определить, как изображение, или обрезать часть текстовой области.
Только после этих настроек запускаем процесс распознавания. Сканы имеют множественные дефекты: повреждения символов (из-за некорректной бинаризации), искажение символов (в результате геометрической коррекции) и мусор в виде точек. Как следствие, по первому тому Книги Памяти Удмуртии в среднем 1% символов помечен, как неуверенно распознанные.
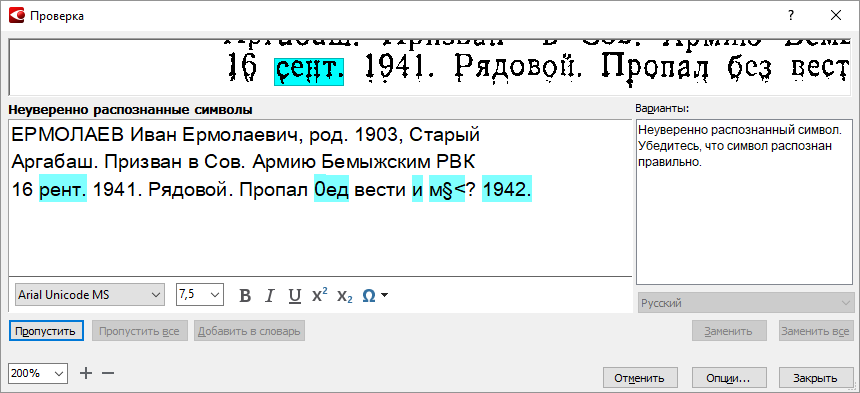
Дальше начинается самый трудоемкий этап - проверка неуверенно распознанных символов и несловарных слов. Обращу внимание на два момента:
- Если попадается некорректное определение абзацев, необходимо прервать проверку и исправить форматирование
- Если ошибки повторяются, их можно исправить автозаменой, в моем случае «Приззан в Сов. Армию» или «Призван в Сок. Армию» встречались на каждом 5 листе. Но автозаменами необходимо пользоваться очень осторожно. На основе собственного неудачного опыта настоятельно рекомендую не использовать автозамены для исправления имен, фамилий и наименований географических объектов.
Результат экспортируем в два файла: pdf и txt. pdf позднее будем использовать как оригинал, по которому будем сверять потенциальные ошибки. Из txt можно сразу скопировать текст в таблицу Excel.
Я рекомендую также использовать распознавание с обучением. Это значительно улучшает качество распознавания.
Некоторые часто повторяющиеся слова и сокращения можно добавить в пользовательский словарь (если обнаруживается, что это слово часто неправильно распознается).
При обработке Омутнинского района столкнулся с большим количеством мусора на сканах. Этот мусор ФР упрямо не хочет игнорировать и распознает как разнообразные символы. Несколько улучшил ситуацию в ФШ (фильтр "Шум/Пыль и царапины", подбирал параметры, затем прогнал пакетно всю папку со сканами). В результате мусора стало меньше, но буквы округлились, сохранив узнаваемость. Далее применил распознавание с обучением, чтобы научить ФР "новому" шрифту.
Субъективное мнение: Распознование с обучением - пустая трата времени. Специалисты компании ABBYY рекомендуют этот метод только для декоративных шрифтов. На нормальное обучение необходимо потратить много времени. В итоге работа разбивается на несколько этапов, и кажется что на проверку тратиться времени меньше, но в сумме трудозатраты на обучение + проверку больше чем просто на проверку. В общем, по-моему это чисто психологическая тема.
По словарю полностью согласен. Когда делал первый район, основная часть ошибок пришлась на фамилии, все новые словоформы добавлял в словарь. В итоге на четвертом районе неуверенно распознанные символы в фамилиях практически не встречались.